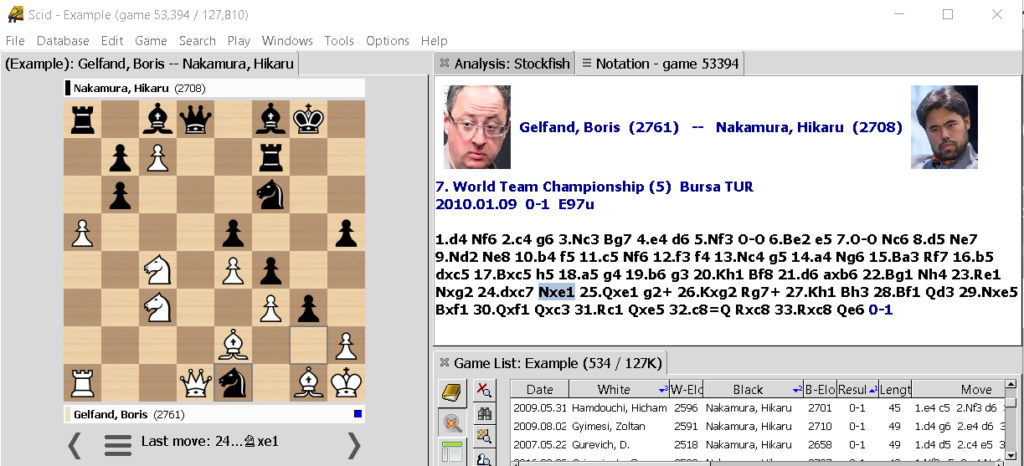
Las bases de datos de partidas de ajedrez son grandes repositorios de información que se utilizan en programas especializados para visualizar y analizar las partidas. Uno de ellos es SCID:
SCID admite base de datos en formato PGN (Portable Game Notation). Dicho formato no puede ser utilizado para cargar los datos en SQL Server, pero pueden cargarse en un dataframe de RStudio a través del paquete “bigchess”:

Luego, ese data frame puede cargarse como una tabla de SQL Server vinculando RStudio con SSMS (SQL Server Management Studio) utilizando los paquetes “DBI” y “RODBC”:


Carga de datos en SQL Server a través de RStudio
La base OTB_HD.PGN (“OTB” es el acrónimo para “On The Board” – partidas presenciales sobre el tablero con los jugadores frente a frente; “HD” refiere a “High Quality” o partidas con jugadores de ranking ELO mayor a 2000) contiene 2.5 millones de partidas de los últimos 150 años. Como ya mencioné arriba, PGN no es un formato admitido por SQL para cargar directamente los datos en SSMS, por lo que la carga se realiza a través de RStudio para cargar los datos en un dataframe y luego enviarlos a SSMS de la siguiente manera:
## LOAD REQUIRED PACKAGES
library("bigchess")
library("RODBC")
library("DBI")
library("RSQLite")
##################
## DEFINE THE PGN DATABASE TO BE UPLOADED INTO RSTUDIO
OTB_db <- "C:\\Users\\Desktop\\OTB-HD.pgn"
##################
## LOAD THE PGN DB. TO KEEP IT MANEAGEABLE, LOAD DATA UP TO MOVE 15 FROM BLACK
con <- gzfile(OTB_db,"rb",encoding = "latin1")
start.time <- Sys.time()
df22 <- as.data.frame(read.pgn.ff(con,ignore.other.games=T,add.tags = c("FEN","ECO","WhiteElo","BlackElo"),extract.moves=15,stat.moves=F,source.movetext=T,last.move=F))
end.time <- Sys.time()
time.taken <- end.time - start.time
time.taken
##################
## LOAD THE DB INTO SQL SERVER THROUGH THE ODBC CONNECTION
##################
connection <- odbcConnect("R-SQLServer_connection")
sqlSave(connection,df22,tablename="OTB_HD",rowname=FALSE,append=TRUE)
Una vez realizado este procedimiento, la tabla puede visualizarse en SSMS:
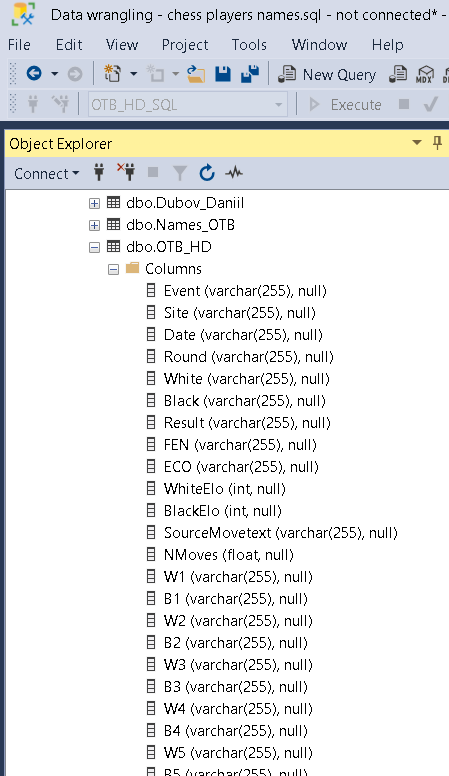
Como puede verse, las columnas contienen datos de cada partida y las movidas tanto de las blancas (con denominación W1 a W15 para la movida 1 hasta la movida 15 de las blancas) como de las negras (B1 a B15).
En este post me voy a concentrar solamente en los nombres de los jugadores, ya que una inspección rápida al dataframe de R me permitió ver que los mismos no tienen la estandarización requerida para realizar un buen análisis.
Para verificar rápidamente los diferentes formatos de nombres, se cargaron los mismos en Tableau para poder visualizarlos. Se vinculó Tableau a la tabla de SQL Server y se realizó un JOIN con otra tabla de Excel para poder identificar aquellos jugadores que fueron campeones mundiales:
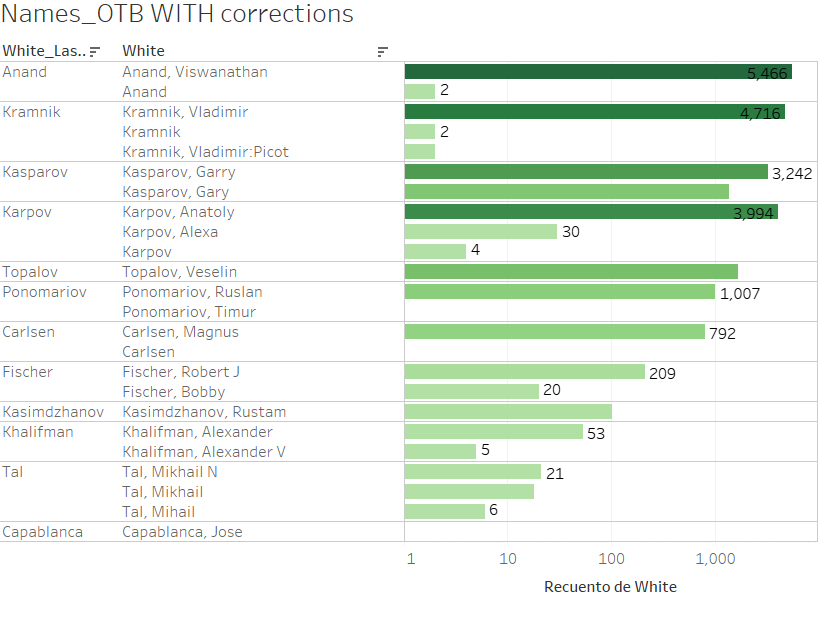
Una tabla rápida del número de partidas de los campeones mundiales muestra los diferentes formatos de nombres que hay en la DB:
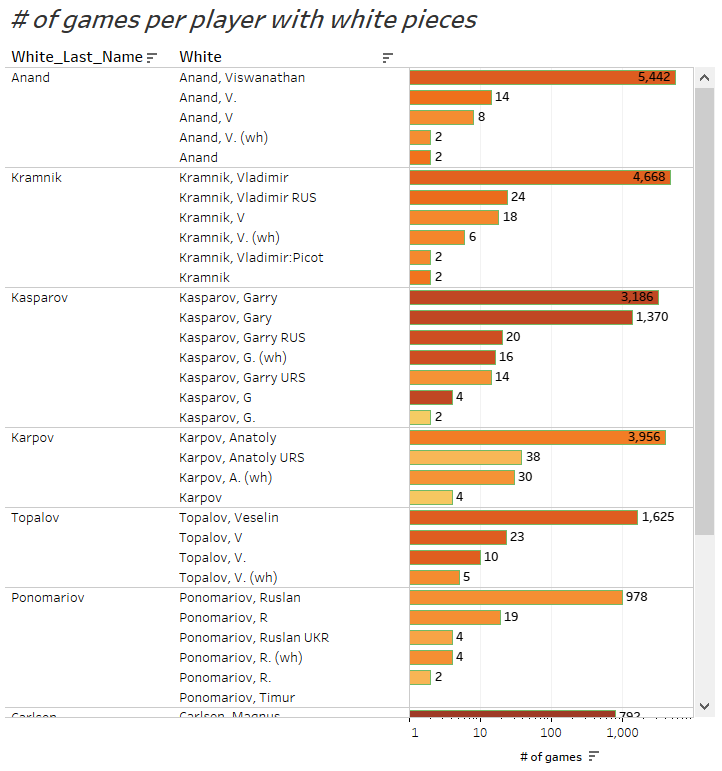
Hay varios patrones diferentes aplicados a los nombres:
- Nombre completo e inicial del nombre, con y sin punto:

- Nombres terminados en “(wh)”, indicando que juega con las piezas blancas (el mismo patrón se repite para las negras):
- ID de país con 3 letras mayúsculas, con y sin paréntesis:

- Otras terminaciones con números y caracteres entre corchetes:
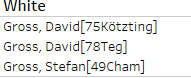
Claramente es necesario estandarizar dichos patrones para poder realizar un análisis correcto.
Estandarización de nombres en SQL Server
PASO 1: creación de tabla temporal
Dado que solamente es necesario trabajar sobre las columnas de nombres, lo mejor es crear una tabla temporal en donde estén solamente la columna de nombres de los jugadores para cada partida. Una vez corregidos los datos en la tabla temporal, se puede hacer un JOIN con la tabla original y reemplazar todos los valores de dicha tabla por los corregidos en la tabla temporal. Para eso es necesario crear un identificador de fila (Index value, ID, etc):
--Fill up new column with Unique Game Identifier (UGI)
DECLARE @UGI INT
SET @UGI = 0
UPDATE OTB_HD_SQL.dbo.OTB_HD
SET @UGI = UGI = @UGI + 1
GO
Luego creamos la tabla temporal “Names_OTB”:
--Creates a temp table to clean up White and Black names
SELECT UGI, White, Black INTO Names_OTB FROM OTB_HD_SQL.dbo.OTB_HD ORDER BY White
PASO 2: limpieza y estandarización de nombres
Para comenzar a corregir los nombres lo hacemos eliminado las siglas “(wh)” y “(bl)” en todas sus variante (con y sin punto)
-- Deletes '. (bl)' and '.(wh)' strings inside names
UPDATE Names_OTB
SET White = REPLACE(White,'.', '') WHERE RIGHT(White,1) = '.'
UPDATE Names_OTB
SET Black= REPLACE(Black,'.', '') WHERE RIGHT(Black,1) = '.'
UPDATE Names_OTB
SET Black = REPLACE(Black,'. (bl)', '')
UPDATE Names_OTB
SET White = REPLACE(White,'. (wh)', '')
UPDATE Names_OTB
SET Black = REPLACE(Black,' (bl)', '')
UPDATE Names_OTB
SET White = REPLACE(White,' (wh)', '') Se eliminan las siglas entre “[]” utilizando expresiones REGEX:
-- Deletes weird expressions in backets inside names
UPDATE Names_OTB --REPLACE doesn't understand REGEX expresions; SUBSTRINGS with PATINDEX shuld be used instead
SET Black = REPLACE(Black,Substring(White, PatIndex('%[[]%]%', White), PatIndex('%]%', White)-PatIndex('%[[]%]', White)+1), '')
UPDATE Names_OTB --REPLACE doesn't understand REGEX expresions; SUBSTRINGS with PATINDEX shuld be used instead
SET White = REPLACE(White,Substring(White, PatIndex('%[[]%]%', White), PatIndex('%]%', White)-PatIndex('%[[]%]', White)+1), '')
PASO 3: Completar el nombre de pila en aquellos nombres que tienen solo la inicial del mismo
Para esto se realizan dos CTE, una para cada color, y luego se hace el JOIN a la tabla temporal
--------------------------------------------------------------
--Adds first name for those names with last names only
WITH onlyLastNames_wth AS (SELECT COUNT(White) AS moreGames, White, LEFT(White,CHARINDEX(',',White)-1) AS onlyLName
FROM Names_OTB
--WHERE LEFT(White,CHARINDEX(',',White) = '' --White NOT LIKE '%,%' AND White NOT LIKE '% %'
WHERE White LIKE '%,%'
GROUP BY White)
,
onlyLastNames_blk AS (SELECT COUNT(Black) AS moreGames, Black,LEFT(Black,CHARINDEX(',',Black)-1) AS onlyLName
FROM Names_OTB
--WHERE LEFT(White,CHARINDEX(',',White) = '' --White NOT LIKE '%,%' AND White NOT LIKE '% %'
WHERE Black LIKE '%,%'
GROUP BY Black)
UPDATE Names_OTB
SET White = CASE WHEN n.White NOT LIKE '%,%' AND n.White NOT LIKE '% %' THEN w.White ELSE n.White END,
Black = CASE WHEN n.Black NOT LIKE '%,%' AND n.Black NOT LIKE '% %'THEN b.Black ELSE n.Black END
FROM Names_OTB as n
LEFT JOIN onlyLastNames_wth as w
ON n.White = w.onlyLName
LEFT JOIN onlyLastNames_blk as b
ON n.Black = b.onlyLName
SELECT *
FROM Names_OTB
WHERE Black LIKE 'Anand' '%,%' --AND White NOT LIKE '% %'
--------------------------------------------
--------------------------------------------
-- For names with first char of first name, finds the following entry where the first name is complete
WITH r_wth AS (
SELECT White, next_complete_name,Last_Name,next_last_name,First_Name, next_first_name
FROM (SELECT DISTINCT White,
LEAD(White,1) OVER (ORDER BY White) AS next_complete_name,
LEAD(LEFT(White,CASE WHEN (CHARINDEX(',',White)-1) < 1 THEN 1 ELSE (CHARINDEX(',',White)-1) END),1)
OVER (ORDER BY White) AS next_last_name,
LEAD(RIGHT(White,CASE WHEN (LEN(White)-CHARINDEX(',',White)-1)<1 THEN 1 ELSE LEN(White)-CHARINDEX(',',White)-1 END),1)
OVER (ORDER BY White) AS next_first_name,
LEFT(White,CASE WHEN (CHARINDEX(',',White)-1) < 1 THEN 1 ELSE (CHARINDEX(',',White)-1) END) AS Last_Name,
RIGHT(White,CASE WHEN (LEN(White)-CHARINDEX(',',White)-1)<1 THEN 1 ELSE LEN(White)-CHARINDEX(',',White)-1 END) AS First_Name
FROM Names_OTB) AS qw
WHERE White <> next_complete_name
AND LEN(First_Name) <=2
AND Last_Name = next_last_name
AND First_Name = LEFT(next_first_name,1)
--ORDER BY White
),
r_blk AS (
SELECT *
FROM (SELECT DISTINCT Black,
LEAD(Black,1) OVER (ORDER BY Black) AS next_complete_name,
LEAD(LEFT(Black,CASE WHEN (CHARINDEX(',',Black)-1) < 1 THEN 1 ELSE (CHARINDEX(',',Black)-1) END),1)
OVER (ORDER BY Black) AS next_last_name,
LEAD(RIGHT(Black,CASE WHEN (LEN(Black)-CHARINDEX(',',Black)-1)<1 THEN 1 ELSE LEN(Black)-CHARINDEX(',',Black)-1 END),1)
OVER (ORDER BY Black) AS next_first_name,
LEFT(Black,CASE WHEN (CHARINDEX(',',Black)-1) < 1 THEN 1 ELSE (CHARINDEX(',',Black)-1) END) AS Last_Name,
RIGHT(Black,CASE WHEN (LEN(Black)-CHARINDEX(',',Black)-1)<1 THEN 1 ELSE LEN(Black)-CHARINDEX(',',Black)-1 END) AS First_Name
FROM Names_OTB) AS qb
WHERE Black <> next_complete_name
AND LEN(First_Name) <=2
AND Last_Name = next_last_name
AND First_Name = LEFT(next_first_name,1)
--ORDER BY Black
)
UPDATE Names_OTB
SET White = CASE WHEN r_wth.next_complete_name IS NULL THEN n.White ELSE r_wth.next_complete_name END,
Black = CASE WHEN r_blk.next_complete_name IS NULL THEN n.Black ELSE r_blk.next_complete_name END
FROM Names_OTB as n
LEFT JOIN r_wth
ON n.White = r_wth.White
LEFT JOIN r_blk
ON n.Black = r_blk.Black
SELECT UGI, White
FROM Names_OTB
Resultados
Como puede verse, la mayoría de las inconsistencias en los nombres han desaparecido y quedan algunos detalles menores por ajustar para tener los datos correctamente estructurados: