Uno de ingredientes más fantásticos que se utilizan a la hora de hacer cerveza es el lúpulo:

Esta planta trepadora genera unas flores que una vez cosechadas y adicionadas a la olla de cocción son las responsables principales de aportarle amargor y aroma a las cervezas. Originalmente habia solo un puñado de variedades de lúpulos, pero en las últimas décadas, con el auge de la cerveceria artesanal, las “hop farms” (granjas de lúpulo) lograron expandir las variedades de los mismos haciendo mezclas entre ellos a través de la polinización cruzada. En la actualidad hay más de 260 variedades de lúpulos y el número sigue creciendo a medida que los productores logran nuevas combinaciones. Uno de los productores, Hopsteiner, tiene un excelente catálogo visual de las variedades de lúpulo que ofrece:

A la hora de elegir una clase de lúpulo para nuestra cerveza, en general se hace en función de las características cualitativas que informa el productor (por ej: “aporta aromas cítricos y gusto a frutas tropicales”) . Sin embargo, también se puede realizar un análisis más detallados de los componentes químicos que poseen las flores y que son los que aportan sus cualidades a la cerveza terminada.
Lamentablemente es dificil encontrar una base de datos técnicos de cada estilo de lúpulo, pero en el sitio http://www.hopslist.com/hops/ se detallan aproximadamente 264 variedades de lúpulos con sus especificaciones técnicas:
En la imágen de abajo se ven los datos técnicos especificados por la página, entre ellos el % de alfa ácidos (aportan amargor) y los aceites escenciales (Co-Humulone) que aportan aroma y gusto:

Semejante cúmulo de información no podia pasar sin ser foco de análisis. Esta web debía ser scrapeada!.
Algoritmo de scraping (Python)
Para comenzar, importamos los módulos request (para accesar páginas web), BeautifulSoup (para realizar el “parse” y filtrado de los datos de la pagina web) y pandas (postprocesamiento):
import requests
from bs4 import BeautifulSoup
import pandas as pd Se carga la página desde donde se va a realizar el scraping:
page = requests.get("http://www.hopslist.com/hops/") El próximo paso es realizar el “parse” de la página con BeautifulSoup:
soup = BeautifulSoup(page.content, 'html.parser') Para poder entrar al link de cada uno de los lúpulos, se realiza la búsqueda de todos los items “li” con class = ‘listing-item’. Luego se generan dos listas: una con el nombre de los lúpulos (hp) y otro con la dirección web de cada uno (web). Esta última es la que se accederá con el una función de scrapeo para poder extraer los datos requeridos:
hops= soup.find_all('li', class_='listing-item') # finds all lists with specified class
for hop in hops:
hp=[hop.get_text() for hop in hops ] #stores hop names
web=[str(hop)[str(hop).find('http'):str(hop).find('/">') ] for hop in hops ] #stores web addresses Próximo paso: definir las funciones para poder realizar el scraping dentro de cada elemento de la lista “web”.
La función “reach_hop_detail_page“se usa para filtrar la tabla que tiene los datos técnicos de cada lúpulo. Luego del estudio de la estructrura de estas páginas de datos se encontró que los mismos se encuentran dentro de una tabla. Dicha tabla puede filtrarse a partir del atributo “width”, que para algunos lúpulos tiene un valor de “620” y para otros “100%”, por lo que se requirió adaptar la función.
def reach_hop_detail_page(web):
pageDetails = requests.get(str(web)) #(web[everyWeb])
soupDetails = BeautifulSoup(pageDetails.content, 'html.parser')
try:
hop_desc1= str(soupDetails.find("div", {"class" : "entry-content content"}).find("p", recursive=True))
hop_desc2= str(soupDetails.find("div", {"class" : "hopsl-content"}).next_sibling.next_sibling)
hop_data_aux= soupDetails.find("table", {"width" : "620"}).findAll("td", recursive=True)
except:
hop_desc1= str(soupDetails.find("div", {"class" : "entry-content content"}).find("p", recursive=True))
hop_desc2= str(soupDetails.find("div", {"class" : "hopsl-content"}).next_sibling.next_sibling)
hop_data_aux= soupDetails.find("table", {"width" : "100%"}).next_sibling.findAll("td", recursive=True)
return hop_data_aux Por otro lado, la función “extract_hops_details” extrae el texto de la tabla seleccionada con la función anterior.
def extract_hops_details(hop_data,details_or_data):
hop_aux=[None]
if details_or_data=="data":
for i in range(1,45,2): #extracts hop data
hop_aux.append(hop_data[i].get_text())
return hop_aux
else:
for i in range(0,44,2): #extracts table column names
hop_aux.append(hop_data[i].get_text())
return hop_aux Último paso antes de realizar el scraping: guardar los nombres de los parámetros que están siendo scrapeados (algo que también se realiza con la función “extract_hops_details”, ya que los mismos están en la tabla filtrada)
#Extracts hop details column names
hop_data=reach_hop_detail_page(web[1])
details_column_names =extract_hops_details(hop_data,"details") Listo!. Llegó el momento de realizar el scraping. El mismo se hace de la siguiente manera:
1) se define la lista vacía en donde se van a guardar los parámetros técnicos de cada lúpulo
2) Para cada elemento de la lista “web” (o sea, para cada hoja técnica de cada uno de los lúpulos listados) se ejecuta lo siguiente:
a. Se accede a la página con la tabla de datos técnicos y se filtra la misma
b. Se extraen los datos técnicos de la tabla filtrada
c. Se guarda la nueva lista como un nuevo elemento de la lista madre creada en el punto 1)
hop_details_list=[None]
#print(reach_hop_detail_page(web[19]))
for anyweb in range(0,len(web)):
hop_data=reach_hop_detail_page(web[anyweb])
next_hop_details=extract_hops_details(hop_data,"data")
hop_details_list.append(next_hop_details) Luego de correr (lo que toma unos minutos, ya que tiene que acceder a aproximadamente 264 páginas de datos técnicos) los datos se ven así:
print(hop_details_list[1]) Lo que es muy poco útil. Para llevarlo a un dataframe en el que se puedan observar los datos se utiliza Pandas, y luego de algunas transformaciones y de agregarle los nombre de columnas filtrados más arriba se obtiene el dataframe con los datos scrapeados:
df=pd.DataFrame({"d":hop_details_list})
df=df["d"].apply(pd.Series)
df.columns =details_column_names
df=df.iloc[1:,1:] #drops the first column
hop_df=pd.DataFrame({
"Hops":hp,
"www":web,
})
hop_df = pd.concat([hop_df , df.reset_index(drop=True)], axis=1)
hop_df 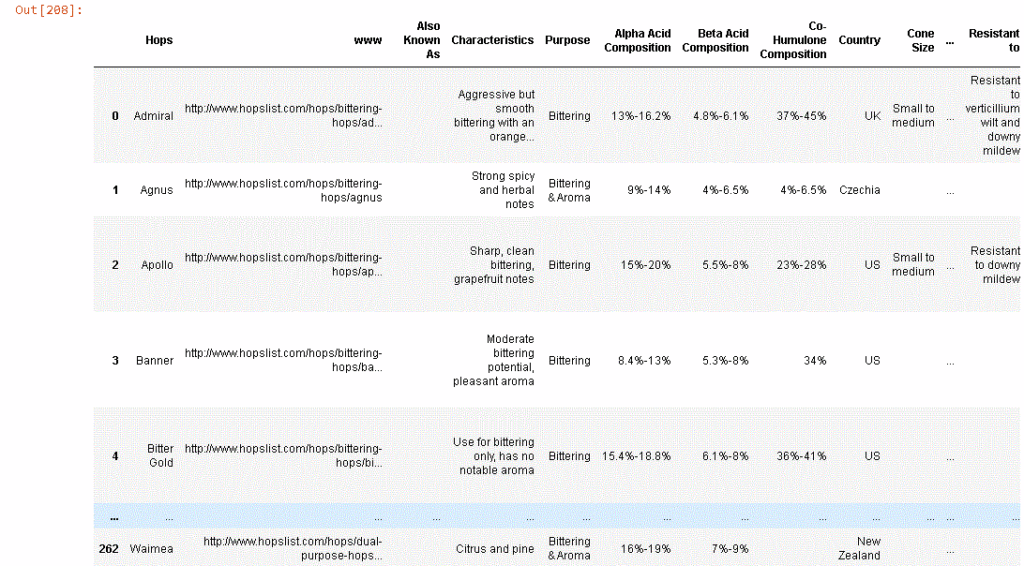
Y aquí está el producto final: 266 observaciones o variedades de lúpulos con 24 columnas de datos para cada uno.
Próximo paso: realizar la limpieza y estructurar los datos para poder analizarlos, pero eso es parte de otro post…